
天若OCR批量文字识别是天若OCR的另一个版本,作写独立编写,软件支持jpg,jpeg,png,bmp以及pdf几种格式,自动转换成word文件,并支持简单的排版,让用户提高效率。
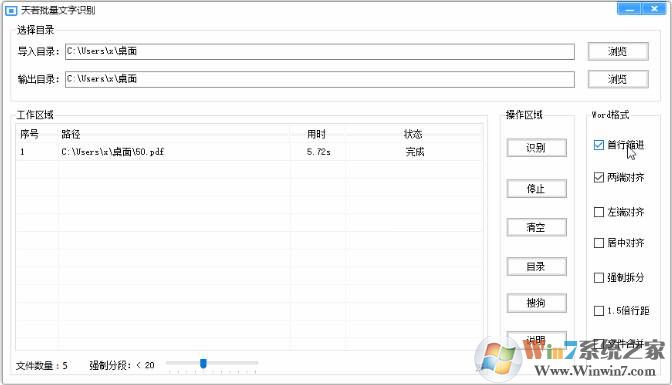
关于pdf识别流程(建议本身是图片的pdf文档使用该软件):
1.pdf转换成图片。
2.图片OCR成文字。
关于排版:
1.支持自动分段。
2.界面上有个强制分段的滑块,表示一个阀值,当识别的一行的文本个数小于该数值时,强制分段。
由于时间原因,该软件仅仅进行接口维护。
1.1更新
1.优化了下排版接口。
2.增加了工作区域滚动条。
1.2更新
1.支持tif格式图片
2.增加了工作区域可以进行Ctrl+↑或Ctrl+↓进行移动,同时可以进行拖动方便排版。
3.对于导入的文档顺序进行了部分优化。
使用方法:
关于pdf识别流程(建议本身是图片的pdf文档使用该软件):
1.pdf转换成图片。
2.图片OCR成文字。
关于排版:
1.支持自动分段。
2.界面上有个强制分段的滑块,表示一个阀值,当识别的一行的文本个数小于该数值时,强制分段。
由于时间原因,该软件仅仅进行接口维护。
1.1更新
1.优化了下排版接口。
2.增加了工作区域滚动条。
1.2更新
1.支持tif格式图片
2.增加了工作区域可以进行Ctrl+↑或Ctrl+↓进行移动,同时可以进行拖动方便排版。
3.对于导入的文档顺序进行了部分优化。
使用方法:
1.选择目录或者拖入文件。
2.选择word配置。
3.点击识别按钮。
4.等待识别完成。
5.对于表格区域,按住Ctrl+上键(下键)可以进行移动。
滑块作用:更改某行文本小于某个数值时强制分段